Posts

How PyTorch Sees Your Triton Kernel: Using ReLU Kernel in Model with Dynamo and AOT Autograd Backend
How to write Triton Kernel, wire it into model with full gradient support, and then trace the entire …

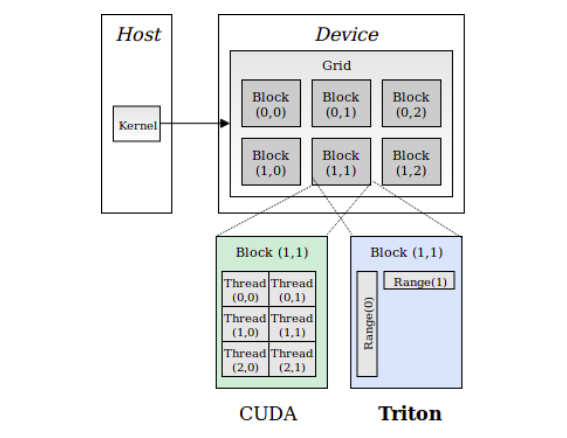
Understanding Triton Kernels from First Principles
A deep dive into how Triton kernels work, explained from absolute basics to complete understanding. …
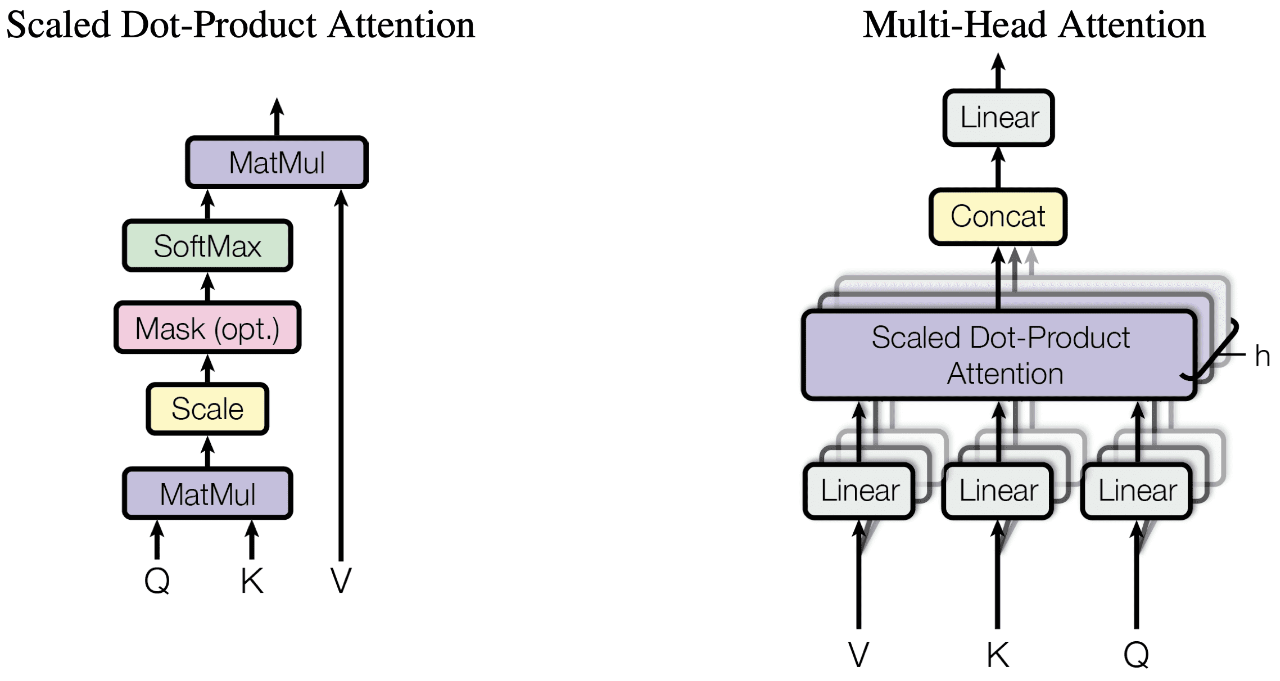
Under the Hood: How PyTorch Chooses Attention Kernels and Why It Matters for Performance
A deep dive into PyTorch’s attention kernel selection and what each choice means for your …
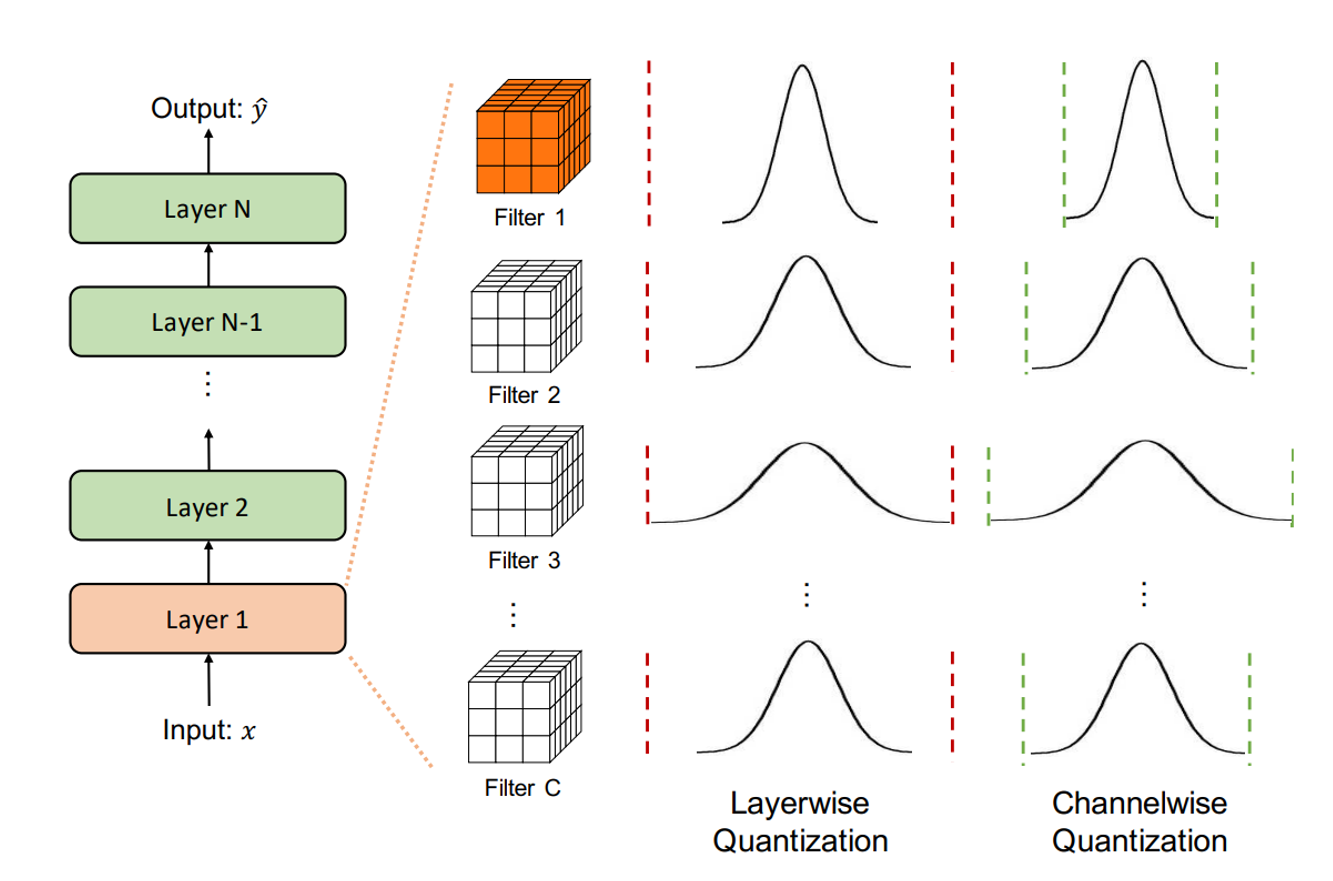
From Theory to Practice: Quantization and Dequantization Made Simple
Quantization transforms floating-point values (‘float32’) into lower-precision formats, such as …

Breaking Down Vision Transformers: A Code-Driven Explanation
In this article, I’ll break down the layers of a ViT step by step with code snippets, and a …
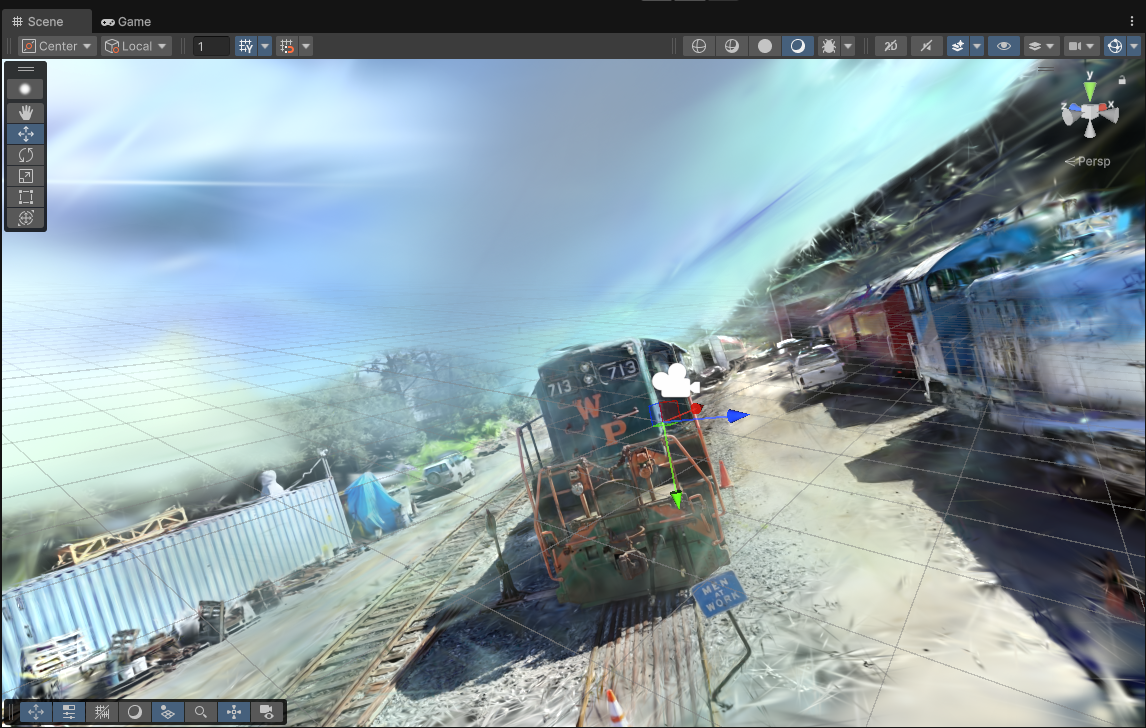
Turn 3D Gaussian Splat Files into Stunning Assets in Unity 6
This guide walks you through the process of loading splat files in Unity 6 using the Gaussian …