How PyTorch Sees Your Triton Kernel: Using ReLU Kernel in Model with Dynamo and AOT Autograd Backend


How to write Triton Kernel, wire it into model with full gradient support, and then trace the entire compilation pipeline — from Python source to the AOT Autograd graph — so you understand exactly what torch.compile does with your custom op.
Important: this implementation is intentionally a teaching example. It keeps pieces separate so the pipeline is easy to inspect. For production performance, prefer fused ops/kernels (for example fused activation + bias/residual paths, and fused backward) to reduce memory traffic and launch overhead.
We will use LeNet as the vehicle: simple enough to read in one sitting, realistic enough to show every stage of the pipeline.
1. The Triton ReLU Kernel
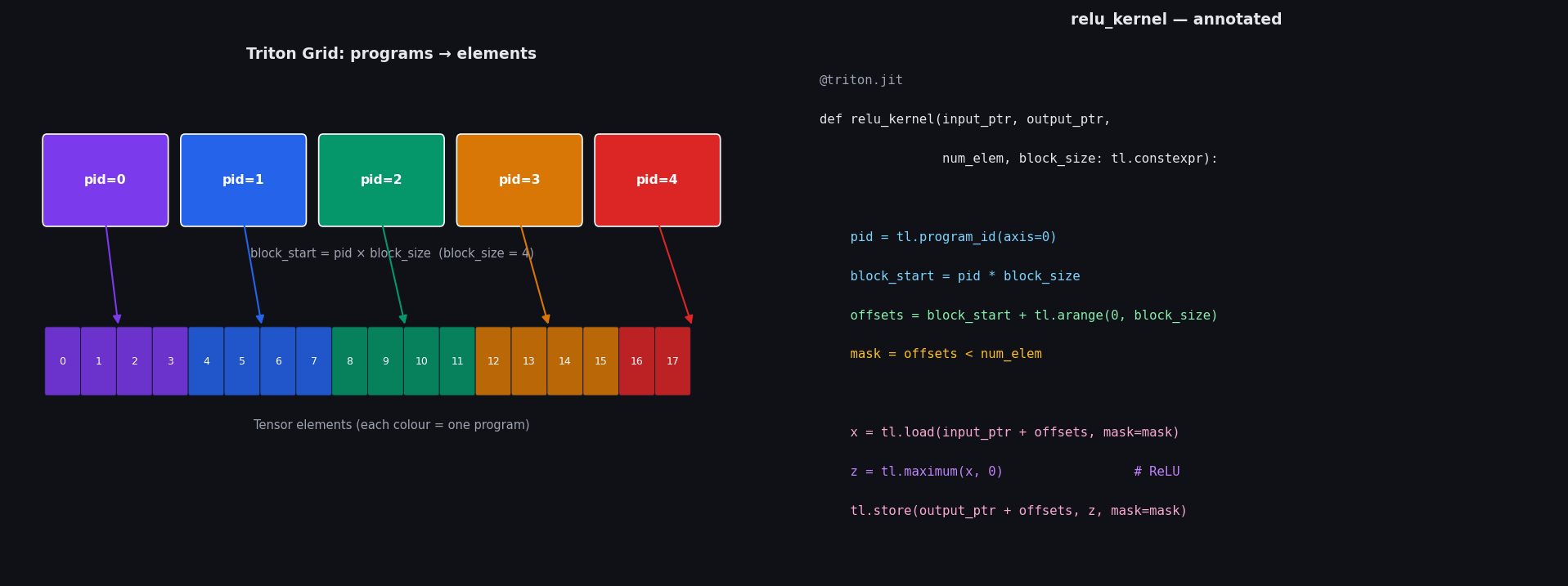
import triton
from triton import language as tl
@triton.jit
def relu_kernel(input_ptr, output_ptr, num_elem, block_size: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * block_size
offsets = block_start + tl.arange(0, block_size)
mask = offsets < num_elem
x = tl.load(input_ptr + offsets, mask=mask)
z = tl.maximum(x, 0)
tl.store(output_ptr + offsets, z, mask=mask)
How to read this line by line: for a deeper foundation, see Understanding Triton Kernels from First Principles.
The Python launcher:
def triton_relu(x):
output = torch.empty_like(x)
num_elem = x.numel()
block_size = 1024
grid = lambda meta: (triton.cdiv(num_elem, meta['block_size']),)
relu_kernel[grid](x, output, num_elem, block_size=block_size)
return output
triton.cdiv(num_elem, block_size) is ceiling division — it computes how many programs we need so that every element is covered. With block_size=1024 and, say, 18 816 elements (a [4, 6, 28, 28] tensor), that is 18816/1024 = 19 programs. That grid of 19 programs runs concurrently on the GPU.
2. Making the Kernel Differentiable
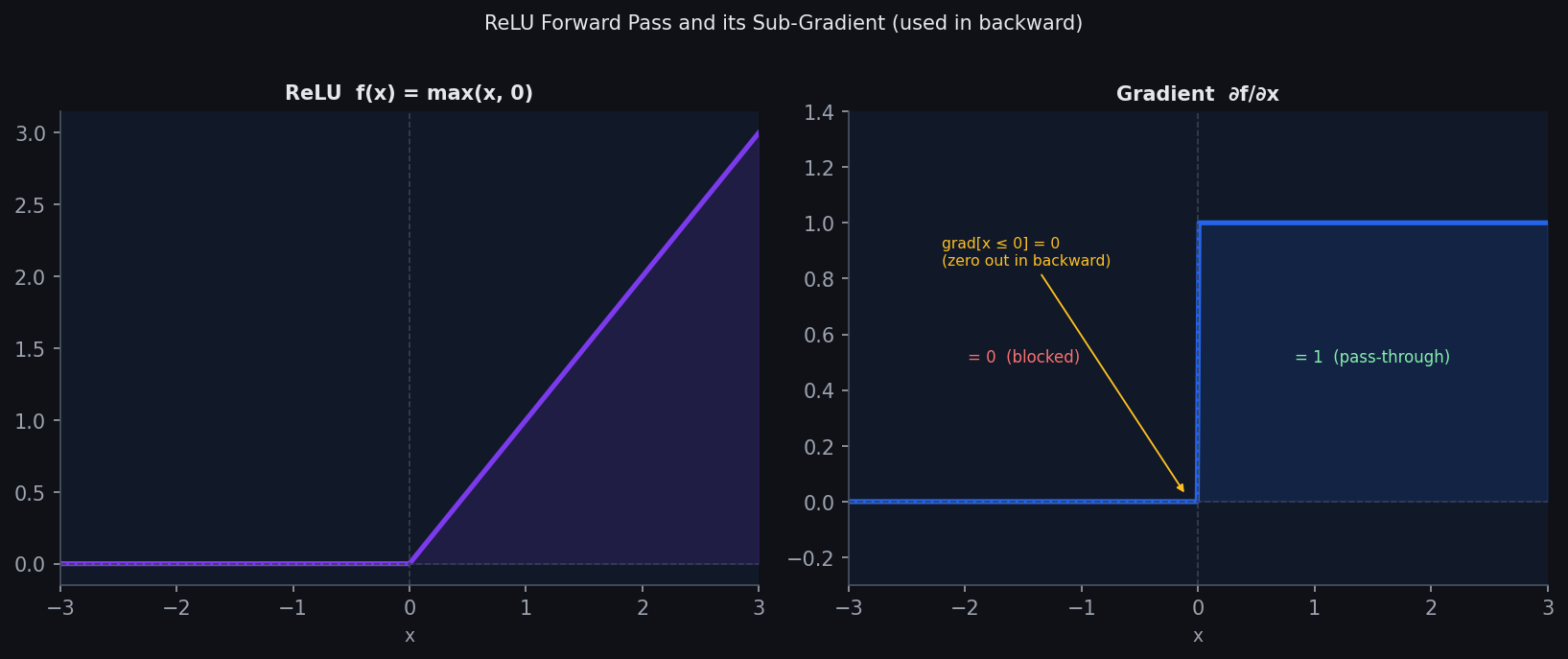
triton_relu is a raw GPU call. PyTorch’s autograd engine has no idea how to backpropagate through it. torch.autograd.Function is the bridge:
class TritonReLUFn(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x) # stash x so the backward can read it
return triton_relu(x)
@staticmethod
def backward(ctx, grad_output):
(x,) = ctx.saved_tensors
grad = grad_output.clone()
grad[x <= 0] = 0 # ReLU sub-gradient: 0 where x ≤ 0
return grad
The math: ReLU is:
$$f(x) = \max(x, 0)$$Its derivative is:
$$\frac{\partial f}{\partial x} = \begin{cases} 1 & x > 0 \\ 0 & x \leq 0 \end{cases}$$So during backprop, the upstream gradient grad_output just passes through wherever the pre-activation input was positive, and is zeroed out elsewhere. That is exactly what grad[x <= 0] = 0 does.
Wrapping in an nn.Module makes it a drop-in replacement for nn.ReLU():
class TritonReLU(nn.Module):
def forward(self, x):
return TritonReLUFn.apply(x)
3. Building LeNet with TritonReLU
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.convnet = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2),
TritonReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5, padding=2),
TritonReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(16 * 7 * 7, 120),
TritonReLU(),
nn.Linear(120, 84),
TritonReLU(),
nn.Linear(84, 10),
)
def forward(self, x):
x = self.convnet(x)
x = self.fc(x)
return x
The architecture is unchanged from the 1998 original. The only difference from a stock PyTorch implementation is that every nn.ReLU() has been replaced with TritonReLU(). The 4 activations in the network — after Conv1, Conv2, Linear(784→120), Linear(120→84) — will each dispatch to our custom Triton kernel.
Tensor shape flow through the convnet:
Input → [4, 1, 28, 28]
Conv2d(1→6) → [4, 6, 28, 28] (padding=2 preserves spatial dims)
TritonReLU → [4, 6, 28, 28]
MaxPool2d(2×2) → [4, 6, 14, 14]
Conv2d(6→16) → [4, 16, 14, 14]
TritonReLU → [4, 16, 14, 14]
MaxPool2d(2×2) → [4, 16, 7, 7]
Flatten → [4, 784]
Linear(784→120)→ [4, 120]
TritonReLU → [4, 120]
Linear(120→84) → [4, 84]
TritonReLU → [4, 84]
Linear(84→10) → [4, 10] (logits)
4. Stage 1: The Dynamo FX Graph
torch.compile begins with Dynamo, which symbolically traces the forward method and converts it into an FX graph — a data structure that represents the computation as a list of nodes. We can intercept this graph by writing a custom backend:
def test_backend(gm, inputs):
print(gm.code) # Python source of the traced graph
gm.graph.print_tabular() # node table
return gm.forward # return the original forward unchanged
input = torch.rand(4, 1, 28, 28).to("xpu")
model = LeNet().to("xpu")
model = torch.compile(model, backend=test_backend)
model(input)
Full Output — the traced Python source:
def forward(self,
L_self_modules_convnet_modules_0_parameters_weight_,
L_self_modules_convnet_modules_0_parameters_bias_,
L_x_,
L_self_modules_convnet_modules_3_parameters_weight_,
L_self_modules_convnet_modules_3_parameters_bias_,
L_self_modules_fc_modules_1_parameters_weight_,
L_self_modules_fc_modules_1_parameters_bias_,
L_self_modules_fc_modules_3_parameters_weight_,
L_self_modules_fc_modules_3_parameters_bias_,
L_self_modules_fc_modules_5_parameters_weight_,
L_self_modules_fc_modules_5_parameters_bias_):
input_1 = torch.conv2d(l_x_,
l_self_modules_convnet_modules_0_parameters_weight_,
l_self_modules_convnet_modules_0_parameters_bias_,
(1, 1), (2, 2), (1, 1), 1)
fwd_body_0 = self.fwd_body_0
bwd_body_0 = self.bwd_body_0
input_2 = torch.ops.higher_order.autograd_function_apply(
fwd_body_0, bwd_body_0, input_1,
args_tensor_mask=[True], non_differentiable_idx=[])
input_3 = torch.nn.functional.max_pool2d(input_2, 2, 2, 0, 1,
ceil_mode=False, return_indices=False)
input_4 = torch.conv2d(input_3,
l_self_modules_convnet_modules_3_parameters_weight_,
l_self_modules_convnet_modules_3_parameters_bias_,
(1, 1), (2, 2), (1, 1), 1)
fwd_body_1 = self.fwd_body_1
bwd_body_1 = self.bwd_body_1
input_5 = torch.ops.higher_order.autograd_function_apply(
fwd_body_1, bwd_body_1, input_4,
args_tensor_mask=[True], non_differentiable_idx=[])
input_6 = torch.nn.functional.max_pool2d(input_5, 2, 2, 0, 1,
ceil_mode=False, return_indices=False)
input_7 = input_6.flatten(1, -1)
input_8 = torch._C._nn.linear(input_7,
l_self_modules_fc_modules_1_parameters_weight_,
l_self_modules_fc_modules_1_parameters_bias_)
fwd_body_2 = self.fwd_body_2
bwd_body_2 = self.bwd_body_2
input_9 = torch.ops.higher_order.autograd_function_apply(
fwd_body_2, bwd_body_2, input_8,
args_tensor_mask=[True], non_differentiable_idx=[])
input_10 = torch._C._nn.linear(input_9,
l_self_modules_fc_modules_3_parameters_weight_,
l_self_modules_fc_modules_3_parameters_bias_)
fwd_body_3 = self.fwd_body_3
bwd_body_3 = self.bwd_body_3
input_11 = torch.ops.higher_order.autograd_function_apply(
fwd_body_3, bwd_body_3, input_10,
args_tensor_mask=[True], non_differentiable_idx=[])
input_12 = torch._C._nn.linear(input_11,
l_self_modules_fc_modules_5_parameters_weight_,
l_self_modules_fc_modules_5_parameters_bias_)
return (input_12,)
Full Node table:
opcode name target args / kwargs
───────────── ───────────────────── ────────────────────────── ─────────────────────────────────────────
placeholder conv0_weight L_self_...convnet_0_weight_ ()
placeholder conv0_bias L_self_...convnet_0_bias_ ()
placeholder l_x_ L_x_ ()
placeholder conv1_weight L_self_...convnet_3_weight_ ()
placeholder conv1_bias L_self_...convnet_3_bias_ ()
placeholder fc0_weight L_self_...fc_1_weight_ ()
placeholder fc0_bias L_self_...fc_1_bias_ ()
placeholder fc1_weight L_self_...fc_3_weight_ ()
placeholder fc1_bias L_self_...fc_3_bias_ ()
placeholder fc2_weight L_self_...fc_5_weight_ ()
placeholder fc2_bias L_self_...fc_5_bias_ ()
call_function input_1 torch.conv2d (l_x_, conv0_weight, ...)
get_attr fwd_body_0 fwd_body_0
get_attr bwd_body_0 bwd_body_0
call_function input_2 autograd_function_apply (fwd_body_0, bwd_body_0, input_1)
call_function input_3 max_pool2d (input_2, 2, 2, 0, 1)
call_function input_4 torch.conv2d (input_3, conv1_weight, ...)
get_attr fwd_body_1 fwd_body_1
get_attr bwd_body_1 bwd_body_1
call_function input_5 autograd_function_apply (fwd_body_1, bwd_body_1, input_4)
call_function input_6 max_pool2d (input_5, 2, 2, 0, 1)
call_method input_7 flatten (input_6, 1, -1)
call_function input_8 linear (input_7, fc0_weight, fc0_bias)
get_attr fwd_body_2 fwd_body_2
get_attr bwd_body_2 bwd_body_2
call_function input_9 autograd_function_apply (fwd_body_2, bwd_body_2, input_8)
call_function input_10 linear (input_9, fc1_weight, fc1_bias)
get_attr fwd_body_3 fwd_body_3
get_attr bwd_body_3 bwd_body_3
call_function input_11 autograd_function_apply (fwd_body_3, bwd_body_3, input_10)
call_function input_12 linear (input_11, fc2_weight, fc2_bias)
output output output ((input_12,),)
What this tells us:
Each of our four TritonReLU activations appears as autograd_function_apply(fwd_body_N, bwd_body_N, …). Dynamo has not seen through the autograd.Function — it treats the entire forward+backward pair as an opaque higher-order op. The standard convolutions and linear layers are rendered as ordinary call_function nodes referencing torch.conv2d / torch._C._nn.linear.
5. Stage 2: AOT Autograd — Tracing Forward and Backward Together
test_backend returned the graph unchanged, so no compilation happened. The real pipeline passes through AOT Autograd (aot_module_simplified), which:
- Traces both forward and backward in one symbolic pass.
- Lowers autograd_function_apply nodes into concrete aten ops + triton_kernel_wrapper_functional calls.
- Annotates every tensor with its dtype and concrete shape.
We hook into both compiler slots to print what it produces:
from torch._functorch.aot_autograd import aot_module_simplified, make_boxed_func
def aot_backend(gm, sample_inputs):
def fw(gm, sample_inputs):
gm.print_readable()
return make_boxed_func(gm.forward)
def bw(gm, sample_inputs):
gm.print_readable()
return make_boxed_func(gm.forward)
return aot_module_simplified(gm, sample_inputs,
fw_compiler=fw, bw_compiler=bw)
model = torch.compile(LeNet(), backend=aot_backend).to("xpu")
model(input)
Full Output AOT forward graph:
class GraphModule(torch.nn.Module):
def forward(self,
primals_1: "f32[6, 1, 5, 5]", # Conv1 weight
primals_2: "f32[6]", # Conv1 bias
primals_3: "f32[4, 1, 28, 28]", # input batch
primals_4: "f32[16, 6, 5, 5]", # Conv2 weight
primals_5: "f32[16]", # Conv2 bias
primals_6: "f32[120, 784]", # FC1 weight
primals_7: "f32[120]", # FC1 bias
primals_8: "f32[84, 120]", # FC2 weight
primals_9: "f32[84]", # FC2 bias
primals_10: "f32[10, 84]", # FC3 weight
primals_11: "f32[10]"): # FC3 bias
# ── Conv1 ─────────────────────────────────────────────────────────
convolution: "f32[4, 6, 28, 28]" = torch.ops.aten.convolution.default(
primals_3, primals_1, primals_2,
[1, 1], [2, 2], [1, 1], False, [0, 0], 1)
primals_2 = None
# ── TritonReLU after Conv1 ─────────────────────────────────────────
empty_like: "f32[4, 6, 28, 28]" = torch.ops.aten.empty_like.default(
convolution, pin_memory=False)
triton_kernel_wrapper_functional_proxy = \
torch.ops.higher_order.triton_kernel_wrapper_functional(
kernel_idx=0, constant_args_idx=8,
grid=[(19, 1, 1)], # ceil(18816 / 1024) = 19 programs
tma_descriptor_metadata={},
kwargs={'input_ptr': convolution, 'output_ptr': empty_like},
tensors_to_clone=['output_ptr'])
empty_like = None
getitem: "f32[4, 6, 28, 28]" = \
triton_kernel_wrapper_functional_proxy['output_ptr']
triton_kernel_wrapper_functional_proxy = None
# ── MaxPool1 ──────────────────────────────────────────────────────
max_pool2d_with_indices = \
torch.ops.aten.max_pool2d_with_indices.default(getitem, [2, 2], [2, 2])
getitem_1: "f32[4, 6, 14, 14]" = max_pool2d_with_indices[0]
getitem_2: "i64[4, 6, 14, 14]" = max_pool2d_with_indices[1] # indices saved for backward
max_pool2d_with_indices = None
# ── Conv2 ─────────────────────────────────────────────────────────
convolution_1: "f32[4, 16, 14, 14]" = torch.ops.aten.convolution.default(
getitem_1, primals_4, primals_5,
[1, 1], [2, 2], [1, 1], False, [0, 0], 1)
primals_5 = None
# ── TritonReLU after Conv2 ─────────────────────────────────────────
empty_like_1: "f32[4, 16, 14, 14]" = torch.ops.aten.empty_like.default(
convolution_1, pin_memory=False)
triton_kernel_wrapper_functional_proxy_1 = \
torch.ops.higher_order.triton_kernel_wrapper_functional(
kernel_idx=0, constant_args_idx=9,
grid=[(13, 1, 1)], # ceil(12544 / 1024) = 13 programs
tma_descriptor_metadata={},
kwargs={'input_ptr': convolution_1, 'output_ptr': empty_like_1},
tensors_to_clone=['output_ptr'])
empty_like_1 = None
getitem_3: "f32[4, 16, 14, 14]" = \
triton_kernel_wrapper_functional_proxy_1['output_ptr']
triton_kernel_wrapper_functional_proxy_1 = None
# ── MaxPool2 ──────────────────────────────────────────────────────
max_pool2d_with_indices_1 = \
torch.ops.aten.max_pool2d_with_indices.default(getitem_3, [2, 2], [2, 2])
getitem_4: "f32[4, 16, 7, 7]" = max_pool2d_with_indices_1[0]
getitem_5: "i64[4, 16, 7, 7]" = max_pool2d_with_indices_1[1]
max_pool2d_with_indices_1 = None
# ── FC layers ─────────────────────────────────────────────────────
view: "f32[4, 784]" = torch.ops.aten.view.default(getitem_4, [4, 784])
getitem_4 = None
t: "f32[784, 120]" = torch.ops.aten.t.default(primals_6); primals_6 = None
addmm: "f32[4, 120]" = torch.ops.aten.addmm.default(primals_7, view, t); primals_7 = None
# ── TritonReLU after FC1 ───────────────────────────────────────────
empty_like_2: "f32[4, 120]" = torch.ops.aten.empty_like.default(addmm, pin_memory=False)
triton_kernel_wrapper_functional_proxy_2 = \
torch.ops.higher_order.triton_kernel_wrapper_functional(
kernel_idx=0, constant_args_idx=10,
grid=[(1, 1, 1)], # ceil(480 / 1024) = 1 program
tma_descriptor_metadata={},
kwargs={'input_ptr': addmm, 'output_ptr': empty_like_2},
tensors_to_clone=['output_ptr'])
empty_like_2 = None
getitem_6: "f32[4, 120]" = triton_kernel_wrapper_functional_proxy_2['output_ptr']
triton_kernel_wrapper_functional_proxy_2 = None
t_1: "f32[120, 84]" = torch.ops.aten.t.default(primals_8); primals_8 = None
addmm_1: "f32[4, 84]" = torch.ops.aten.addmm.default(primals_9, getitem_6, t_1); primals_9 = None
# ── TritonReLU after FC2 ───────────────────────────────────────────
empty_like_3: "f32[4, 84]" = torch.ops.aten.empty_like.default(addmm_1, pin_memory=False)
triton_kernel_wrapper_functional_proxy_3 = \
torch.ops.higher_order.triton_kernel_wrapper_functional(
kernel_idx=0, constant_args_idx=11,
grid=[(1, 1, 1)],
tma_descriptor_metadata={},
kwargs={'input_ptr': addmm_1, 'output_ptr': empty_like_3},
tensors_to_clone=['output_ptr'])
empty_like_3 = None
getitem_7: "f32[4, 84]" = triton_kernel_wrapper_functional_proxy_3['output_ptr']
triton_kernel_wrapper_functional_proxy_3 = None
t_2: "f32[84, 10]" = torch.ops.aten.t.default(primals_10); primals_10 = None
addmm_2: "f32[4, 10]" = torch.ops.aten.addmm.default(primals_11, getitem_7, t_2); primals_11 = None
# ── Return: output + everything needed by the backward pass ────────
return (addmm_2,
primals_1, primals_3, primals_4,
convolution, getitem, getitem_1, getitem_2,
convolution_1, getitem_3, getitem_5,
view, t, addmm, getitem_6, t_1, addmm_1, getitem_7, t_2)
What changed compared to the Dynamo graph:
Three critical transformations happened:
Custom ops lowered to device kernels: Each autograd_function_apply(fwd_body_N, …) became triton_kernel_wrapper_functional(kernel_idx=0, grid=[(N,1,1)], …). Dynamo saw your Triton op as an opaque black box; AOT Autograd opened it up and linked it to the actual GPU kernel.
Shapes concretized: Dynamo’s graph had no tensor shape information. AOT Autograd annotated every tensor with its concrete dtype and shape: “f32[4, 6, 28, 28]”. This matters: the grid size computation (19, 13, 1, 1 programs) is only possible when you know the exact tensor size.
Weights flattened to arguments: In the Dynamo graph, weights were module attributes (L_self_modules_convnet_0_parameters_weight_). In the AOT graph, they are plain function arguments (primals_1, primals_2, …). This makes the graph stateless and easier for the compiler to reason about.
Backward state packed into return: Dynamo returned only the logits. AOT Autograd returned logits + 18 saved tensors (intermediate activations, pool indices, etc.) needed to compute gradients. The compiler now has everything it needs to generate both forward and backward code.
Return value:
tensor([[ 0.0359, -0.0539, 0.1029, 0.0510, -0.1029, -0.0747, -0.0963, -0.0808,
-0.0912, 0.1353],
[ 0.0284, -0.0546, 0.1088, 0.0551, -0.0985, -0.0691, -0.0970, -0.0784,
-0.1004, 0.1275],
[ 0.0271, -0.0518, 0.1043, 0.0524, -0.0985, -0.0783, -0.0952, -0.0736,
-0.0945, 0.1324],
[ 0.0328, -0.0578, 0.1068, 0.0543, -0.1013, -0.0709, -0.0945, -0.0791,
-0.1006, 0.1293]], device='xpu:0',
grad_fn=<CompiledFunctionBackward>)
The grad_fn=
6. The Full Pipeline at a Glance
Python model
│
▼ torch.compile() + Dynamo tracing
FX Graph (Dynamo)
• conv2d, max_pool2d, linear → call_function nodes
• TritonReLU → autograd_function_apply(fwd_body_N, bwd_body_N)
│
▼ AOT Autograd (aot_module_simplified)
AOT Forward Graph
• conv2d → aten.convolution.default
• ReLU → triton_kernel_wrapper_functional(kernel_idx=0, grid=[(N,1,1)])
• All tensors annotated with concrete dtype + shape
• Return includes saved activations for the backward
│
▼ Backend compiler (Inductor / custom)
Device code (SPIR-V / PTX)
The key insight: your Triton kernel is a first-class citizen at every stage. Dynamo wraps it in autograd_function_apply. AOT Autograd lowers it to triton_kernel_wrapper_functional with concrete grids. The downstream compiler sees it as just another op to schedule alongside convolutions and matrix multiplications.